GPT-3 opened up a competitive market for generative AI for copywriting tools
Marketing has been a hot vertical for generative AI, helped by the fact that marketers have been “open” to AI assisted tools having experienced them through Google and Meta ad products. SEOs in particular have created content with algorithms through “spun” content for years; generative AI copywriting is simply the next step. So it’s no wonder companies are aggressively pursuing the Marketing+AI market, in particular, tools that help marketers generate content & creative assets.
AI-assisted or generated copywriting is one of the more exciting vertical-specific applications, and with the leaders in the categories a few years in–we can start drawing some lessons around go-to-market.
Three key players in this space — Copy.ai, Writer.ai, and Jasper.ai—have grabbed mind and market share, with Copy.ai and Jasper.ai in the obvious lead. These two front-runners have used slightly different approaches bringing their products to market: different channels, different use cases, and, importantly, different pricing… with varied success.
So what can we learn?
Copy.ai vs. Jasper.ai – A Early AI GTM Case Study
Building in public – social drives growth & funding
Both companies are relatively new – Copy.ai started in October 2020 while Jasper launched in 2021. But Copy.ai built in public (aka posting everything about the company on Twitter) so we have a clearer view of their rapid growth.
Copy.ai founder, Paul Yaccoubian, made it a point to build the company in public, sharing not only about the product’s development, but the company’s rapid increase in recurring revenue. The company launched in October 2020, hit $1M ARR by April 14th, 2021, and then $10M ARR by October, 2022.
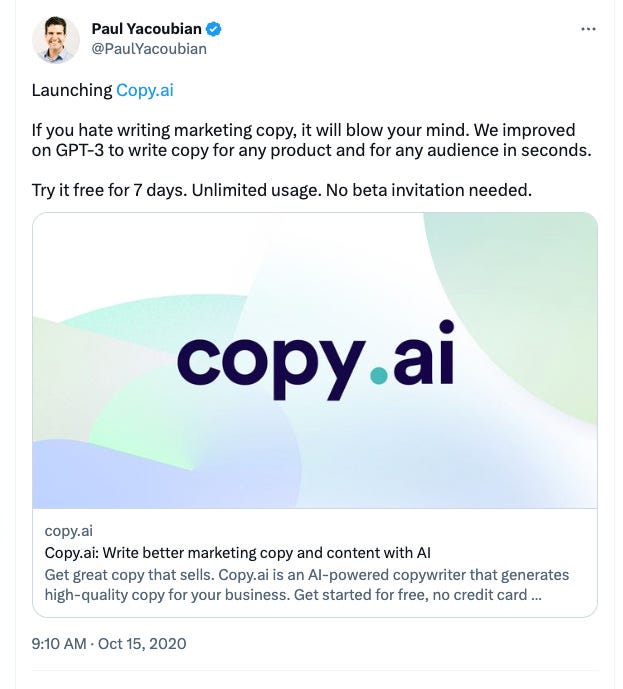
The launch
Growth
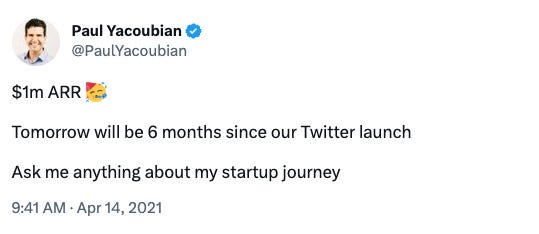
$10M ARR
Impressive growth.
When we look at this from a marketing/GTM lens, we can see that the strategy of building in public & leaning into social created a flywheel: social brought in users, which drove growth. Growth created exciting social content, which drove more users and even an investment from Craft Ventures. This was a smart, founder-led strategy that paid off across many areas of the business. But we’ll see that leaning too heavily into social might not have been the best strategy for copy.ai…
Initial segment choice and growth channel “held” copy.ai back
So Copy.ai obviously grew a ton, and social media gave them an organic channel. But social media as a primary acquisition channel is challenging (this is a whole other topic for another time), especially as the company’s growth coincided with the twitter drama of 2022 & 2023 and its ensuing impacts on advertisers and users (again, a topic for another time.)
Copy.ai did wade into paid media, but initially narrowed their segment focus to marketers–specifically helping marketers with ad copy. The market size for text ad copy optimization is small, especially in search ads. That kind of narrow targeting is hard to scale, and we can see copy.ai has since adjusted their strategy to focus on general writing. This broader approach has opened more keyword volume to the company, but the question remains: is there sufficient demand for these products in paid acquisition channels?
Jasper.ai used zero-interest rate blitzkrieg tactics to win the market
Despite being the latest entrant, Jasper.ai quickly made waves, achieving $100 million in annual recurring revenue (ARR) in just two year, surpassing all competitors.
What did they do differently? Well, alot.
Jasper approached their target market, pricing & packaging, fundraising, and growth strategies completely differently than copy.ai. Jasper.ai went after overall content writing (a larger market than ad copy), charged a higher price point, and used paid ads to grow faster vs. focusing on social.
What do I think made the biggest difference for Jasper?
A higher price point and more capital raised.
The starting price point for Copy.AI is free, $18 for Writer, and $36 for Jasper. Jasper has also raised $120M compared to $26M for Writer and $14M for Copy.ai.
Their higher pricing and capital stack supports higher acquisition costs, enabling Jasper.ai to invest more heavily in marketing efforts. According to Similarweb (yes, questionable veracity), Jasper spends over $1M a month on paid search versus $100k for Copy.ai and barely anything for Writer. Their funding has enabled Jasper to hire more (they have 5x as many employees as either company) and invest more in sales and marketing. All this gives Jasper a big lead on usage, a key moat, versus other alternatives.
Organic sounds nice, but classic GTM strategies work (even in AI)
The fast, organic growth of Generative AI products like ChatGPT or Langchain, have predisposed current companies to zero cost acquisition. However, it’s clear there’s a significant advantage in using more traditional go-to-market methods, like ….. The effective use of these channels can give AI startups the early boost that helps in a winner-takes-most category.
AI companies shouldn’t forget, startups have always used aggressive investment as an effective GTM strategy, effectively outspending their competitors to get the early lead. This worked for companies like Uber early on, and can (and does!) work for generative AI startups as well.
The question is – how will the available channels for these products evolve over time, and if investable dollars is no longer the differentiator–who is going to be more creative, effective, or aggressive with their GTM?
AI GTM Lessons Learned:
- Scale and usage matter – they create a flywheel that benefits all parts of your business
- A social-first strategy has its limits
- Traditional paid ads should play a role in Generative AI application go-to-market
- It’s okay to be late, especially if you target the better segment (and have more cash)